CodeBork | Tales from the Codeface
The coding blog of Alastair Smith, a software developer based in Cambridge, UK. Interested in DevOps, Azure, Kubernetes, .NET Core, and VueJS.
Project maintained by Hosted on GitHub Pages — Theme by mattgraham
Having recently started my new gig at Ieso Digital Health (![]() ), I’ve had an opportunity
to reflect on the things I learned building a greenfield service using recommended good testing practices at
CloudHub360. As such, I thought I’d resume my … delayed …
series on testing software.
), I’ve had an opportunity
to reflect on the things I learned building a greenfield service using recommended good testing practices at
CloudHub360. As such, I thought I’d resume my … delayed …
series on testing software.
Everything I describe in these posts is general purpose, applicable across languages, technology stacks, frameworks, and more. If you want to apply them in an existing codebase, you’re probably going to have some rearchitecting to do. If you’re working in a pure Functional language like F#, Haskell, etc., then these principles are going to take a bit of adaptation to that paradigm; if this is you, I would love to talk this through with you!
This post is a sort of TL;DR of the series as as a whole. Yes, it’s quite long, but it’s the series distilled to its essence, drawing together information from a variety of sources into a single place. If you’re after a succinct answer to the question “how do I test my software”, this is about as short as it gets. (Sorry.)
Climbing the testing pyramid
The testing pyramid is a popular visual metaphor created by Mike Cohn in Succeeding with Agile, giving some focus to the topics of “what do I test” and “how do I test this?”.
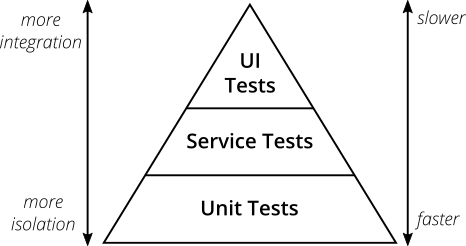
The above representation of the testing pyramid comes from Martin Fowler’s Bliki, in a post by Ham Vocke. Aside from amount of isolation and speed of execution, an additional scale for the pyramid can be the amount of operability that is brought into each: unit tests have none; integration tests include logging; UI tests include metrics/monitoring.
Unit tests
Unit tests are a rock-solid foundation of a high-quality product, when written with the FIRST principles in mind:
- Fast: they should run in milliseconds, no more than 10ms per test.
- Independent: the tests should be able to be run in any order, even in parallel, and not result in different outcomes.
- Repeatable: if a test passes or fails on one run, with no code changes it should produce the same result on the next as well.
- Self-validating: there should be no ambiguity about the result of a test run. Green tick, red cross, whatever.
- Timely: a test should be written with (ideally just before) the code that makes the test pass.
In Visual Studio, NCrunch holds me to these principles better than anything else I’ve ever come across. If my tests can’t run in NCrunch while I’m working, I’ve missed one of these FIRST principles. In front-end testing, I have my unit tests running in watch mode.
Integration tests
Integration tests have their place in every product’s test suite, but should be utilised less than unit tests: these will be slower than the <10ms requirement for unit tests. However, the other FIRST principles apply just as much as they do for unit tests.
The key difference between integration tests and unit tests is that integration tests are for, well, integration: database queries, API calls, filesystem interactions, … All the stuff that’s not business logic! As a result, logging is as important in these tests as it is in production: failures will generally be as a result of changes in the environment rather than functionality.
I often run integration tests in NCrunch: the option to filter to impacted tests only ensures that I’m not waiting ages for each integration test to run on each change. This is often the case with watch mode in front-end tests as well: Jest in particular filters tests in watch mode to those changed since the last commit.
End-to-end tests
These tests cover the full stack and the application infrastructure, with two differing goals in mind. As such, they should be divided into two sets along the lines of those goals.
The key differences between end-to-end tests and integration tests are the amount of integration in play: they don’t test the integration with just one system, they test the integration with all of them at once. These should be easily runnable on developer machines as well as the CI server, and be runnable against both a production-like environment (in a the CI server) and an environment consisting of emulators and similar test doubles (on a developer machine).
Acceptance tests
The goal of acceptance tests is to demonstrate, in a repeatable and self-validating fashion, that the product or service as a whole does what it sets out to achieve. Acceptance tests are often, but need not necessarily, be written in the language of acceptance criteria using an implementation of Gherkin.
Acceptance tests should be run automatically in a build pipeline, pre-deployment. They should also be runnable easily during development so developers can check their work.
System tests
System tests are there for us as programmers to be sure that the product works when fully assembled; you may know them as “smoke tests”, “build verification tests” or similar. There should only be a handful of these covering the things that we (as a company) really care about. As with all other types of test, they should be repeatable and self-validating.
System tests should be run automatically as part of a deployment pipeline, in all environments (production and pre-production). The particularly important ones&emdash;i.e., the ones ensuring core service availability, revenue, etc.&emdash;should run on a periodic basis in production, so that we can verify our metrics are collected.
Integration tests vs. Mocking
I’ve seen both these things go wrong in various code bases. Integration tests often fall into the trap of including business logic, becoming what J. B. Rainsberger refers to as integrated tests. These quickly become painful, because:
- They do not run as quickly as unit tests, providing much slower feedback
- They are testing multiple things: integration and business logic
Faced with a large and slow suite of integrated tests, I see teams turn to mocking libraries to ease the pain caused by the first point, but without addressing the second. They then end up with tests that have complex setup—the stack of integrated layers is replaced with a stack of mocks and stubs—and these become brittle, dependent on the implementation of the behaviour rather than the behaviour itself.
I’ve also seen teams mocking libraries they are consuming, or jumping through hoops to mock the dependency without mocking the library directly. Let’s dig into this more closely.
Coding for integration tests: Hexagonal architecture
GOOS states that tests should only mock things we own; any external dependency should have integration tests instead. This has some ramifications for how we build our product, pushing more towards a hexagonal architecture where loosely-coupled components communicate through a series of domain-specific “ports’ and “adaptors” plugging into those ports. Luckily, both “ports” and “adaptors” have clear parallels in object-oriented languages: interfaces and implementations.
Let’s consider the example of retrieving a set of users from a database. We have an interface IUserRepository and an
implementation CosmosDbUserRepository as follows:
// The interface is the port to the outside world
public interface IUserRepository
{
IEnumerable<User> GetAllUsers();
}
// Meanwhile, the implementation is how the outside world talks to our application
public class CosmosDbUserRepository : IUserRepository
{
private readonly Container _container;
public CosmosDbUserRepository(Container cosmosContainer) =>
_container = cosmosContainer ?? throw new ArgumentNullException(nameof(cosmosContainer))
public IEnumerable<User> GetAllUsers()
{
// I know there would be async-await bits here; they're redacted for clarity
var feedIterator = container.GetItemQueryIterator<dynamic>("select * from U");
while (feedIterator.HasMoreResults)
{
var response = feedIterator.ReadNextAsync();
foreach (var item in response)
{
yield return item;
}
}
}
}
There are two things to note here:
- The port and adaptor are defined in terms of the domain: they are specific to the domain concept of Users.
- The adaptor consumes the dependency directly: there’s no intermediary application-specific layer. We just “plug in” CosmosDB to our application.
Collaboration and Contract testing
Following hexagonal architecture, we can easily apply the principles of collaboration and contract testing, described by J. B. Rainsberger in his talk and blog series Integrated Tests are a Scam. The basic premise of these tests is that testing across the interface is an integrated test, coming with all the problems previously described; however, we can test up to the interface on both sides and achieve a better result!
From the consumer’s perspective (the thing calling IUserRepository), we can write collaboration tests using a mocking
library to verify that the interface was called correctly, and that the responses returned are handled correctly. For
example (using Xunit.net and NSubstitute):
public class UserController_Should
{
[Fact]
public void Retrieve_the_users_from_the_database()
{
var db = Substitute.For<IUserRepository>();
// SUT = "System Under Test"
var sut = new UsersController(db);
sut.ListUsers();
db.Received(1).GetAllUsers();
}
[Fact]
public void Return_the_single_user_from_the_database()
{
var db = Substitute.For<IUserRepository>();
var expectedUser = new User();
db.GetAllUsers().Returns(new[] { expectedUser });
var sut = new UsersController(db);
var result = sut.ListUsers();
Assert.Equal(expectedUser, result);
}
// ... additional tests for 0, "many", "lots", and "oops"
}
So, you can see here that we have tested collaboration with the dependency both “going in” to the port (calling) and “coming out” from the port (returning).
On the implementation side of the interface, we need a similar set of tests: the mirror image, in fact. These are contract tests, verifying that the provider of the dependency adheres to the contract expected by the consumer.
public class CosmosDbUserRepository_Should
{
private readonly Container _container;
public CosmosDbUserRepository_Should()
{
// CosmosDB config omitted for clarity
var client = new CosmosClient();
var database = client.CreateDatabaseIfNotExists();
_container = database.CreateContainerIfNotExists()
}
[Fact]
public void Return_all_users_from_the_database()
{
var expected = new User();
container.CreateItemAsync(expected);
var sut = new CosmosDbUserRepository(_container);
var actual = sut.GetAllUsers();
Assert.Equal(new[] { expected }, actual);
}
}
Note that we’ve written an integration test here: there’s no business logic, just interaction with CosmosDB. It is also
the mirror image of the collaboration tests we wrote for the UserController: we call GetAllUsers() as the action in
our test, as this is expected by the collaboration tests, and we assert that the implementation returns the items
stubbed by the collaboration tests. This gives us a good two-point rule of thumb:
- Collaboration test expectations each match to a different contract Action
- Collaboration test stubs each match to a different contract Assertion
Make the skeletons walk
When starting a new project, it’s easy to forget some of the details involved and focus only on system functionality. The things that are often missed are the bits where automation really shines: how will we build, deploy, operate this new system? This is where a walking skeleton comes in handy: the smallest amount of code that can possibly be written, tested, built, deployed and operated.
The case for a walking skeleton is described as follows in the book Growing Object-Oriented Software, Guided by Tests (affectionately referred to as “GOOS”), on page 31:
[Acceptance tests] must run end-to-end to give us the feedback we need about the system’s external interfaces, which means we must have implemented a whole build, deploy, and test cycle [to implement the first feature] … Deploying and testing right from the start of a project forces the team to understand how their system fits into the world, [flushing out] the “unknown unknown” technical and organisation risks.
Even without the acceptance tests in place, a walking skeleton is useful, as described in Continuous Delivery (p. 134):
If you don’t have any code or unit tests yet, just create the simplest possible “Hello World” example or, for a web application a single HTML page, and put a single unit test in place that asserts true. Then you can do the deployment … finally you can do the acceptance test [and] … verify that the web page contains the text “Hello World”.
Let’s briefly consider a serverless system running on Azure. An example walking skeleton for this could be:
- An Azure Function listening on an HTTP trigger, always returning 200 OK and “Excelsior!”, perhaps encoded in a JSON
object like
{ rallyingCry: "Excelsior!" } - A React app calling the endpoint defined by the Azure Function, checking the response code, and rendering the response message
- A pair of Pact tests, one for the React app and one for the Azure Function
- Git pre-commit hook configured to automatically lint (and fix) the style of the code being checked in
- An
azure-pipeline.ymlfile describing the build and test CI pipeline(s) - An
azure-pipeline.release.ymlfile describing the deployment CD pipeline(s)
This walking skeleton gives us something we can build, test, deploy, and operate, even though it has no useful functionality. Adding the useful functionality is then just adding flesh to the bones, a much simpler task.
References
- Growing Object-Oriented Software, Guided by Tests by Steve Freeman and Nat Pryce (link)
- Continuous Delivery by Jez Humble and David Farley (link)
- Integrated Tests are a Scam by J. B. Rainsberger (video, blog series)